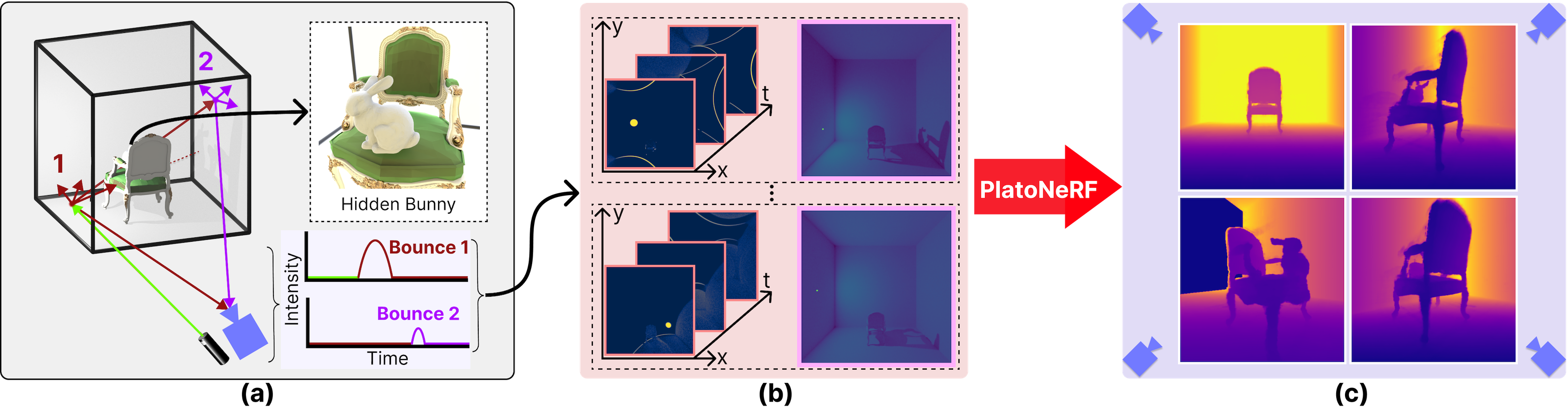
We propose PlatoNeRF: a method to recover scene geometry from a single view using two-bounce signals captured by a single-photon lidar. (a) A laser illuminates a scene point, which diffusely reflects light in all directions. The reflected light illuminates the rest of the scene and casts shadows. Light that returns to the lidar sensor provides information about the visible scene, and cast shadows provide information about occluded portions of the scene. (b) The lidar sensor captures 3D time-of-flight images. (c) By aggregating several such images (by scanning the position of the laser), we are able to reconstruct the entire 3D scene geometry with volumetric rendering.
PlatoNeRF is named after the allegory of Plato's Cave, in which reality is discerned from shadows cast on a cave wall.
Technical Video
Abstract
3D reconstruction from a single-view is challenging because of the ambiguity from monocular cues and lack of information about occluded regions. Neural radiance fields (NeRF), while popular for view synthesis and 3D reconstruction, are typically reliant on multi-view images. Existing methods for single-view 3D reconstruction with NeRF rely on either data priors to hallucinate views of occluded regions, which may not be physically accurate, or shadows observed by RGB cameras, which are difficult to detect in ambient light and low albedo backgrounds. We propose using time-of-flight data captured by a single-photon avalanche diode to overcome these limitations. Our method models two-bounce optical paths with NeRF, using lidar transient data for supervision. By leveraging the advantages of both NeRF and two-bounce light measured by lidar, we demonstrate that we can reconstruct visible and occluded geometry without data priors or reliance on controlled ambient lighting or scene albedo. In addition, we demonstrate improved generalization under practical constraints on sensor spatial- and temporal-resolution. We believe our method is a promising direction as single-photon lidars become ubiquitous on consumer devices, such as phones, tablets, and headsets.
Dataset
We create a dataset of scenes shown above. We train our model and our comparison methods on a single view. Objects are either partially self-occluded or fully occluded from the single training view. Our method and Bounce Flash Lidar are trained on single-view lidar data and S3-NeRF is trained on single-view RGB data.
Visualization of single-photon lidar measurements captured in simulation (bunny in chair dataset). A measurement is captured for each of the 16 unique illumination spots. These videos show the light intensity measured by the lidar over time, and thus the propagation of light in the scene. The first pixel to measure intensity is the point in the scene that is illuminated. Subsequent intensity observed by other pixels corresponds to light that has scattered multiple times. The two-bounce light is used by PlatoNeRF.
Results
Ground Truth
PlatoNeRF
BF Lidar
S3-NeRF
Results across four scenes: chair, dragon, bunny, bunny in chair (from top to bottom).
While PlatoNeRF (top) is able to interpolate across missing pixels due to the use of an implicit representation, Bounce Flash Lidar (bottom) performance significantly degrades as spatial resolution is reduced.
As temporal resolution is reduced (i.e. bin size increased beyond 128 ps), PlatoNeRF (top) maintains smooth reconstructions, while geometry reconstructed by Bounce Flash Lidar (bottom) becomes bumpy (especially noticable on the the floor and walls). Note that the temporal resolution is indicated by the bin size (in picoseconds), with larger bin sizes indicating worse temporal resolution.
Ambient Light and Low Albedo Backgrounds
Ambient Light
Low Albedo Background
PlatoNeRF
S3-NeRF
PlatoNeRF
S3-NeRF
PlatoNeRF is robust both to ambient light (left) and low albedo backgrounds (right), whereas RGB methods often fail, such as shown by S3-NeRF. S3-NeRF is unable to recover geometry with an area light added to the scene (left) and only recovers visible geometry when shadows become hard to detect due to low albedo background (right).
Number of Illumination Points (PlatoNeRF)
16
8
4
2
Results as the number of illumination points used to train PlatoNeRF is reduced from sixteen illumination points (left) to two illumination points (right).
Citation
@inproceedings{PlatoNeRF,
author = {Klinghoffer, Tzofi and
Xiang, Xiaoyu and
Somasundaram, Siddharth and
Fan, Yuchen and
Richardt, Christian and
Raskar, Ramesh and
Ranjan, Rakesh},
title = {{PlatoNeRF}: 3D Reconstruction in {Plato's} Cave via Single-View Two-Bounce Lidar},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2024},
url = {https://platonerf.github.io},
}